Segundo laboratório SRE + AppSec – Alertas e Evidências
Observabilidade para Segurança: Segundo laboratório SRE + AppSec – Alertas e Evidências
No primeiro laboratório eu foquei no básico: transformar um risco simples (falhas de login) em métricas.
Agora era hora de dar o próximo passo natural: transformar essas métricas em alertas e, principalmente, em evidência automática de controle.
A pergunta desta vez foi: se eu digo que tenho controles de acesso e monitoramento, onde está a evidência disso rodando todo dia?
O laboratório
O ponto de partida foi o mesmo app Flask do Dia 1, com três endpoints:
/healthz/login/metrics
O /login continua “inseguro de propósito”: falha aleatoriamente, simulando tanto erros legítimos quanto possíveis tentativas de ataque.
Com o prometheus_client, eu já tinha três métricas principais:
login_requests_total– total de tentativas de loginlogin_failures_total– total de falhas de loginlogin_latency_seconds– latência das requisições de login (histograma)
No Lab 1 isso virava gráficos. No Lab 2, eu quis que isso virasse alertas e evidência de ITGC.
Alertas de segurança com Prometheus
O primeiro passo foi adicionar o Alertmanager e criar uma regra de alertas focada em segurança.
No docker-compose.yml, além do app e do Prometheus, entrou o Alertmanager.
No Prometheus, eu configurei um arquivo só para regras de segurança:
groups:
- name: security-alerts
rules:
- alert: ExcessiveLoginFailures
expr: increase(login_failures_total[5m]) > 15
for: 1m
labels:
severity: high
annotations:
summary: "High failed login attempts"
description: "More than 15 failed login attempts in 5 minutes."
Traduzindo:
“Se, nos últimos 5 minutos, o número de falhas de login aumentar mais do que 15, por pelo menos 1 minuto, dispare um alerta de severidade alta.”
Além disso, criei também:
- alerta de violação de SLO de latência (p95 acima do limite)
- alerta de tráfego muito baixo (sinal de monitoramento cego)
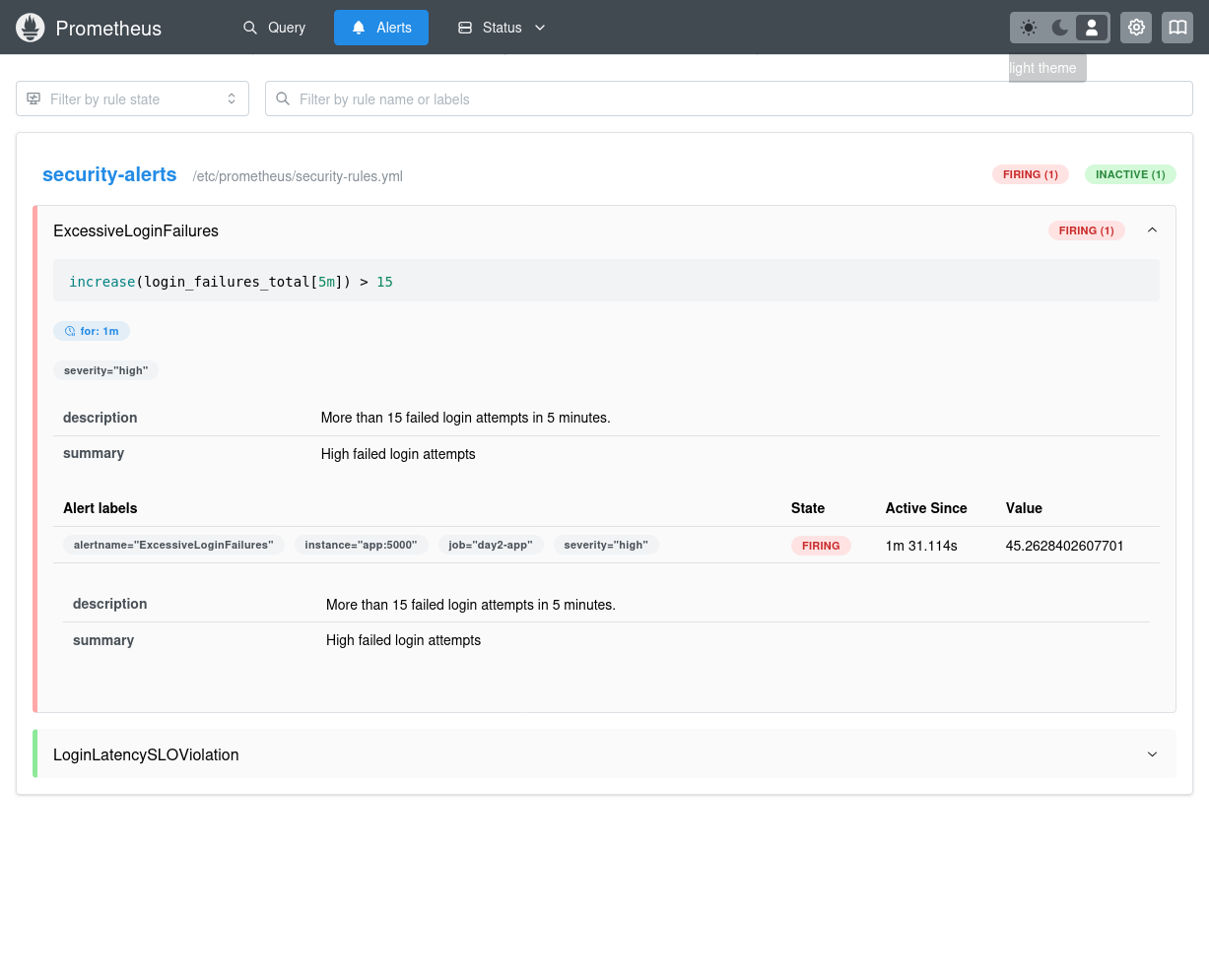
Alertas disparados no Prometheus
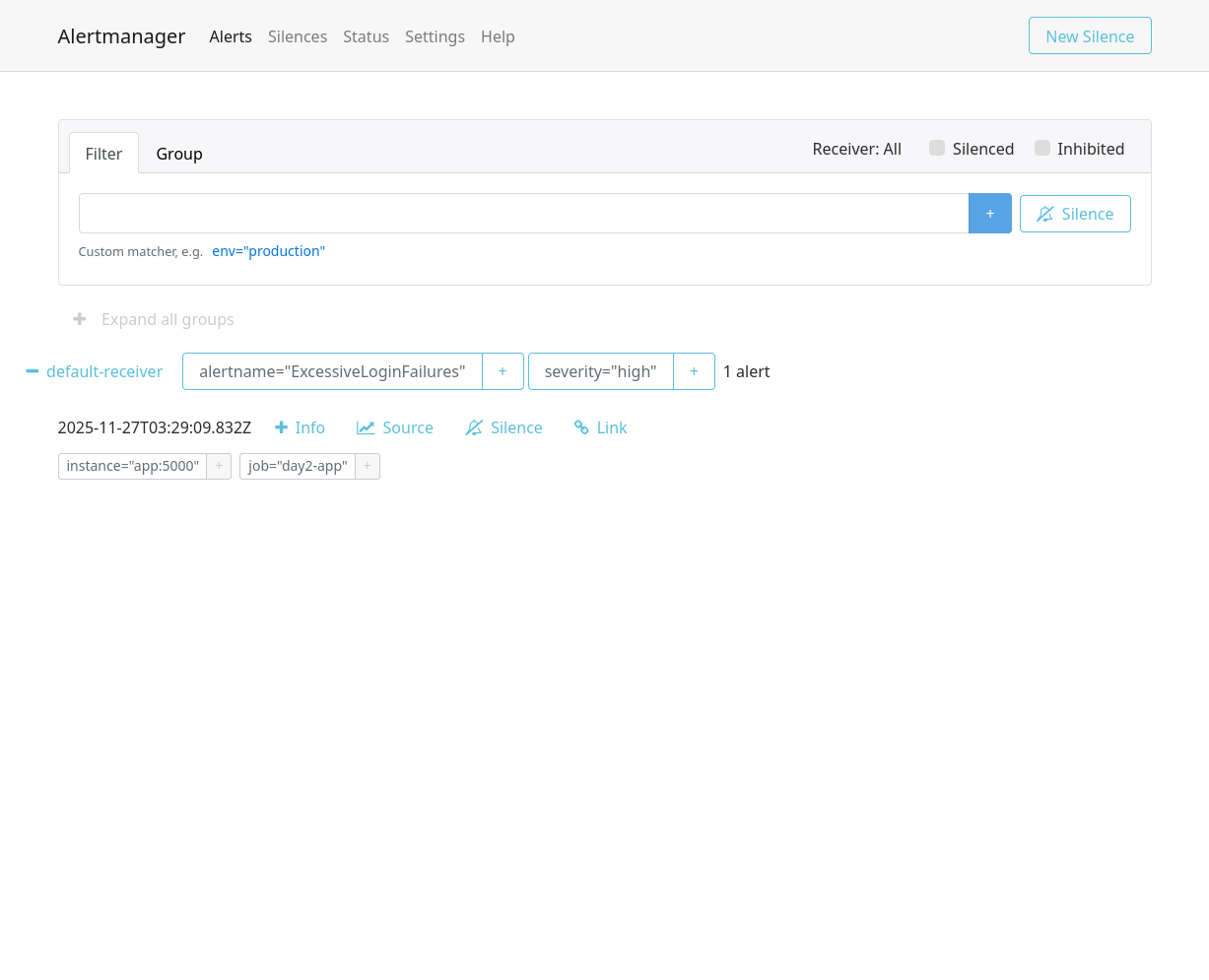
Alertas Recebidos no Alert Manager
Evidência automática para ITGC
A segunda parte foi pensar como auditoria pensa para saber como obter evidência de que esses alertas funcionam.
Criei um script Python que:
- consulta o Prometheus (
/api/v1/query) - coleta as métricas importantes
- salva tudo em
evidence/YYYYMMDD/*.json
Exemplo:
today = datetime.date.today().strftime("%Y%m%d")
os.makedirs(f"evidence/{today}", exist_ok=True)
Isso transforma auditoria de “print de dashboard” em pipeline de evidências.
ITGC em linguagem de métrica
- Acesso lógico →
login_failures_total - Logging & Monitoring →
/metrics+login_requests_total - SLO de controle → latência p95 (
login_latency_seconds_bucket) - Monitoramento de segurança → alertas versionados
- Evidência → JSON diário automaticamente gerado
Por que isso importa?
Com esse lab:
- controles viram números
- evidências deixam de ser manuais
- AppSec ganha uma camada operacional de SRE
- alertas passam a ser parte do ciclo de vida
Esse foi meu Dia 2. Dia 3 vai começar a puxar eventos de nuvem (IAM, CloudTrail, GuardDuty) para dentro dessa mesma lógica.